- Published on
Has Google Killed the Cheap Gemini Models?
- Authors

- Name
- Aymeric Chalochet
A brief history of Gemini's cheapest models
This post retraces the history of Gemini's cheapest model pricing from Gemini 1.5 Flash to Gemini 3.1 Flash Lite, over the course of the past year.
It highlights how the pricing grew approximately 5x for English and 20x for Japanese.
Before starting, it is important to understand the following:
- Gemini 1.5 Flash was priced per character rather than per token like other models.
- The ratio of characters to tokens varies depending on the language. For example, in English, one token is four characters on average; in Japanese, one token is roughly one character.
- The number of characters necessary to express an idea varies depending on the language. When translating long texts between English and Japanese, the Japanese translation has half as many characters as the original text in English.
- Models have different pricing tiers depending on the size of the input/output tokens.
To keep things simple, this post focuses on the cheapest tier each model offers.
Images in the article are screenshots taken from Google's Vertex AI pricing page.
Google removes older models from the pricing page over time. By the time you read this, some models may not be displayed on the Google's page anymore.
Let's dive in!
Gemini 1.5 Flash
Gemini 1.5 Flash was the cheapest of the 1.5 family of models.
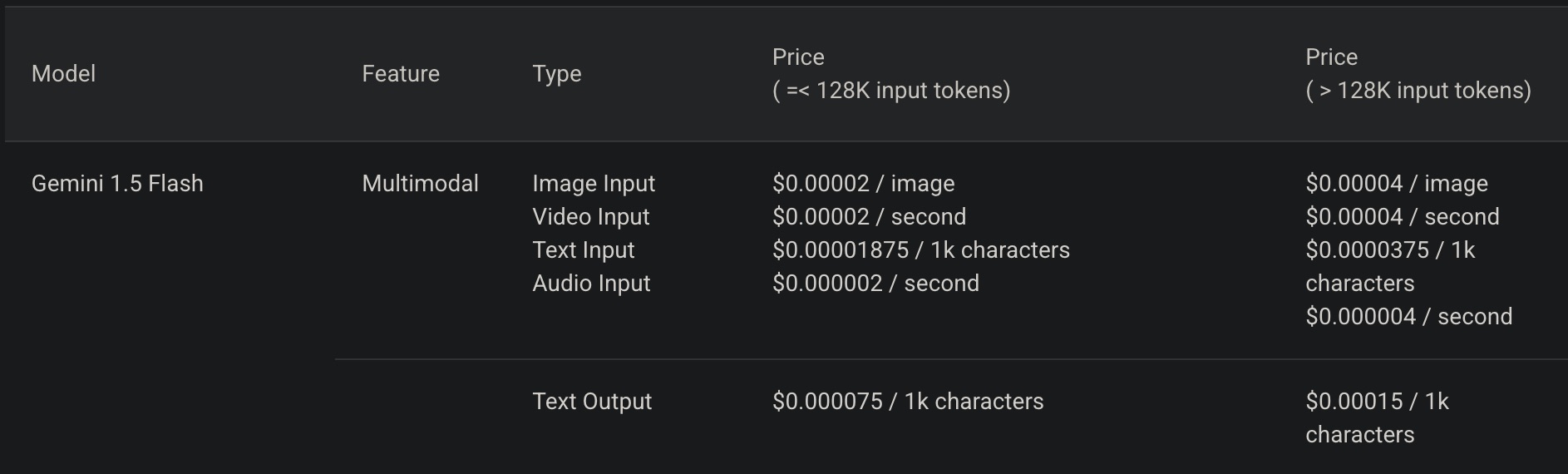
Flash 1.5's pricing was in $ per 1,000 characters. Let's convert this to $ per million tokens for English specifically.
For the conversion, we use four characters per token, then multiply by 1,000 to get to 1M tokens.
Input text: $0.00001875 / 1k characters → $0.075 / 1M tokens
Output text: $0.000075 / 1k characters → $0.3 / 1M tokens
In Japanese, where one token is one character on average:
Input text: $0.00001875 / 1k characters → $0.01875 / 1M tokens
Output text: $0.000075 / 1k characters → $0.075 / 1M tokens
Gemini 2.0 Flash Lite
From the 2.0 model family, Google introduced the new "Flash Lite" model.
"Flash" (without the "Lite") still existed but was more expensive, making 2.0 Flash Lite the direct comparison to 1.5 Flash.
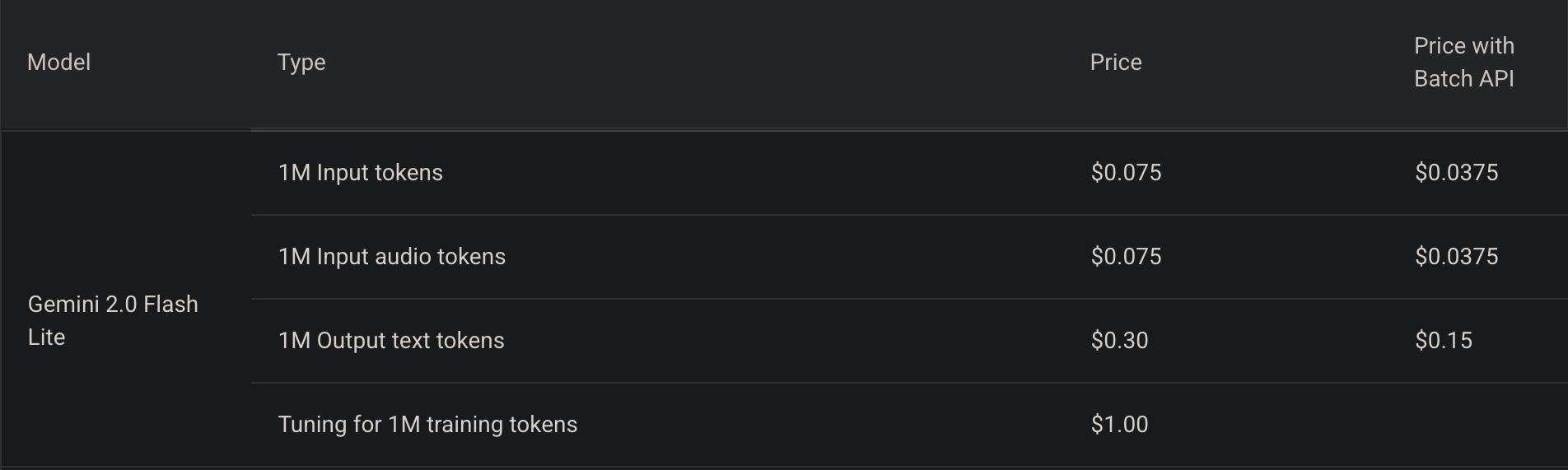
At this point, the pricing remained the same for English.
However, for Japanese, it is a different story.
Input text goes from $0.01875 to $0.075 per million tokens.
Output text goes from $0.075 to $0.3 per million tokens.
That is a 400% increase, or 4x, for both input and output.
Gemini 2.5 Flash Lite
This is when pricing began to climb across the board.
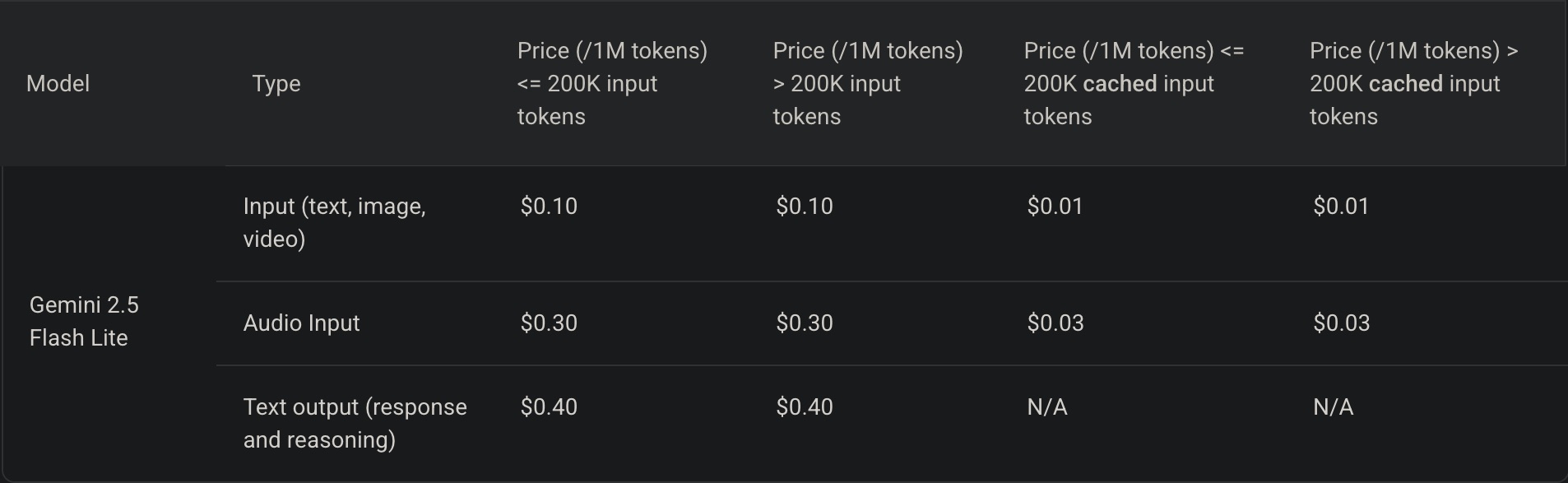
Input text goes from $0.075 to $0.1 per million tokens.
Output text goes from $0.3 to $0.4 per million tokens.
In both cases, that is a 33% increase.
Gemini 3.1 Flash Lite
This is where things get crazy 🤪.
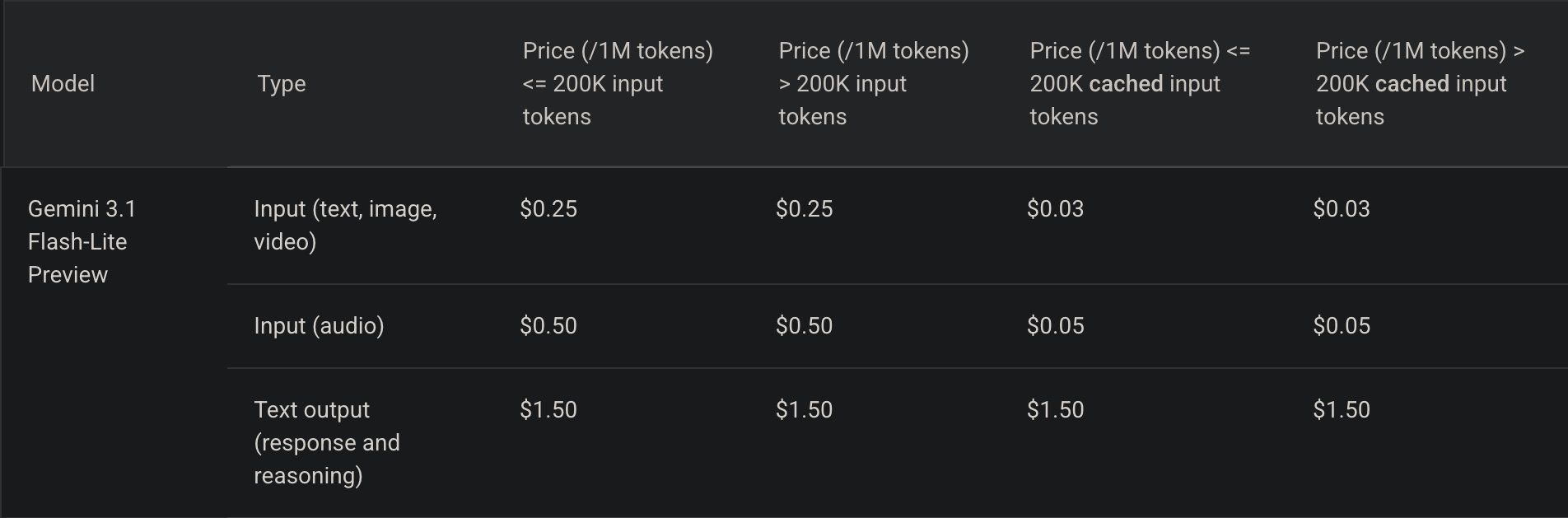
Input text goes from $0.1 to $0.25 per million tokens.
Output text goes from $0.4 to $1.5 per million tokens.
That is a 250% increase for input and 375% for output.
If a request used one million tokens for both input and output, the total cost would average out to a 350% increase.
Aggregated increases
For English, the total price increase is 467%, almost 5x, assuming input and output text both have one million tokens.
Input text: $0.075 to $0.25 per million tokens, 333% increase.
Output text: $0.3 to $1.5 per million tokens, 500% increase.
For Japanese, the total increase is 1866%, almost 20x, assuming input and output text both have one million tokens.
Input text: $0.01875 to $0.25 per million tokens, 1333% increase, or 13.3x.
Output text: $0.075 to $1.5 per million tokens, 2000% increase, or 20x.
Conclusion
I have multiple hypotheses as to why the price increased this much.
Google could be correcting their pricing after initially offering models at a significant discount to drive market adoption. Considering the abundance of open-source small language models (under a few billion parameters) and architectural improvements like Mixture of Experts (as seen in Kimi 2.5), it is also possible that Google decided to stop offering an ultra-cheap model within the Gemini family.
There are many use cases that do not require the performance improvements provided by new generations and would instead benefit from maintaining previous performance at a lower price point.
I hope Google will soon offer an "Extra Lite" Gemini model.